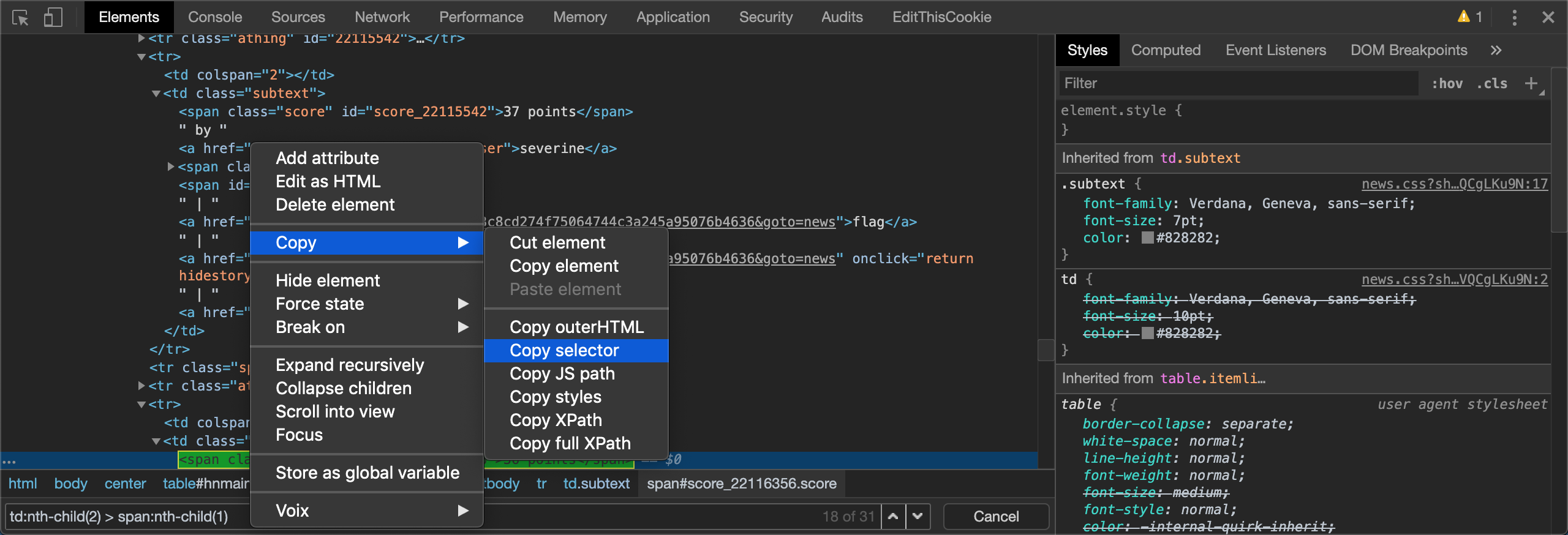
L'objet BeautifulSoup peut accepter deux arguments. Le premier argument est le marquage actuel, et le second argument est l'analyseur que vous souhaitez.
Keep in mind that BeautifulSoup processes static HTML, not JavaScript. It can only use data that would be seen when visiting the webpage with JavaScript disabled .
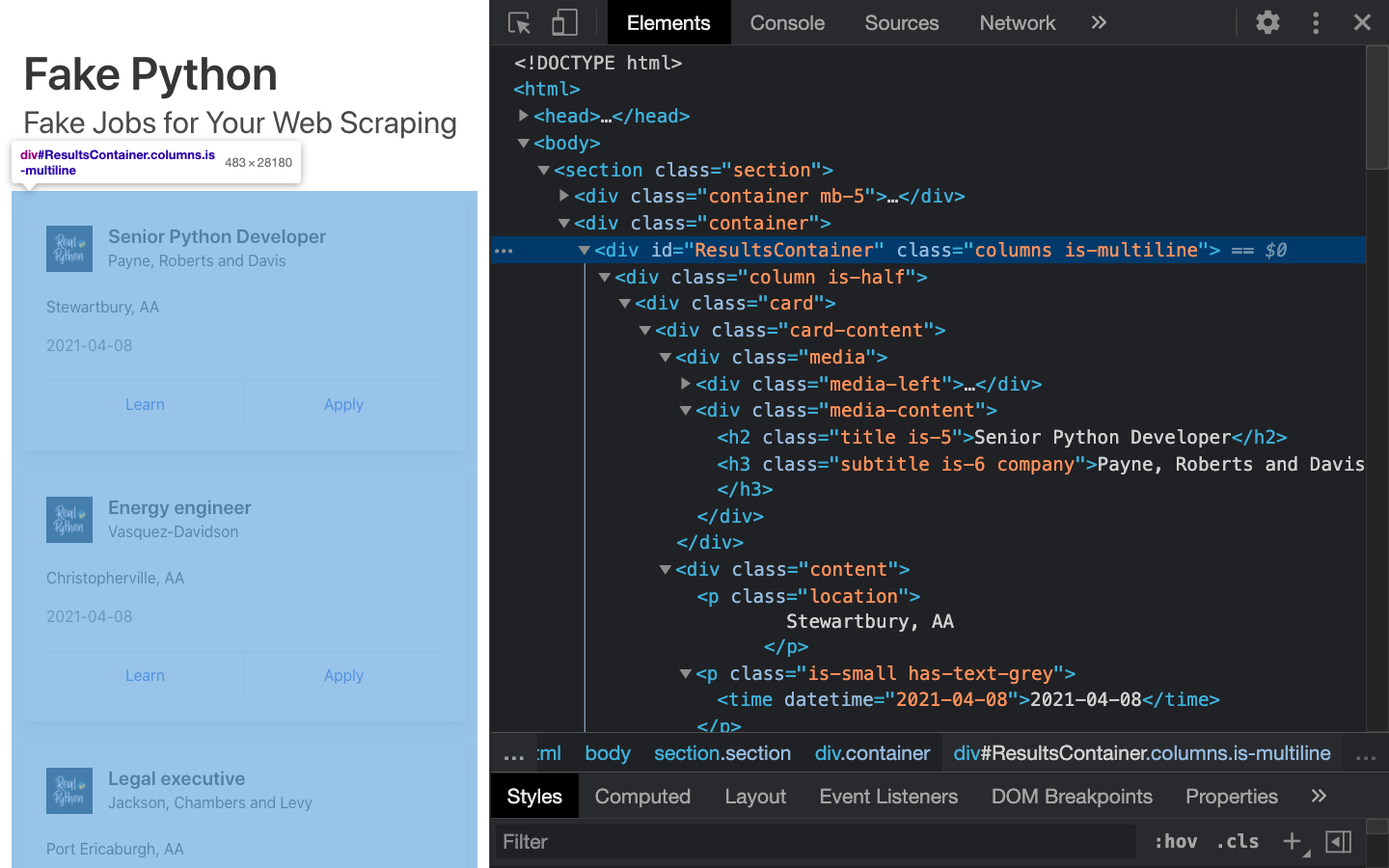
Changing HTML tags with BeautifulSoup. Now that we have our environment setup, we can begin using BeautifulSoup to parse and manipulate it. We.
Si on est dans la phase récupération des données, on souhaiterait avoir accès à toutes les informations présentes sur une page web pour pouvoir faire ensuite.
BeautifulSoup and rvest both involve creating an object that we can use to parse the HTML from a webpage. However, one immediate difference is that.
Para isso nós vamos fazer uma breve introdução ao BeautifulSoup, que nada mais é do que uma ferramenta de raspagem de dados (obtenção de dados na.
Before diving into web scraping with Python and Beautiful Soup, make sure you have the following installed on your system: Python 3: Download and install the.
BeautifulSoup est une bibliothèque Python qui facilite le traitement des données contenues dans des documents HTML. La bibliothèque fournit des outils et des.
BeautifulSoup est composé de différents outils d’analyse syntaxique tels que html, parser, lxml et HTML5lib. Ainsi, vous pouvez essayer différentes méthodes.
from bs4 import BeautifulSoup. To use Beautiful Soup to parse a web page and extract data from it, you first need to download the page’s HTML content. You can.